Fun with generative music, part one

Introduction
As a lazy person, I want to achieve the most by doing the least. As a lazy musician, I want to create music out of thin air at the push of a button. But how? I’ve been thinking about this problem for a while and in this post I will show you my initial approach in solving it.
The Creative Process
Creating music is a rewarding but also time consuming process. From personal experience, the problem is mostly one of creative control. It usually boils down to this: everything you can tweak must be tweaked.
From melody to frequency balancing to reverb levels to stereo panning - you always have the feeling that something can be better and the last 1% of perfection takes 99% of effort. This is why it sometimes takes me 10 years to finish a track: it’s good but never good enough.
The Art Of Letting Go

So, in order to speed up the process, why not accept that some things cannot be controlled? And if you take that to its limit, why not let some other process (say, algorithms) do the dirty work?
Generative Music
Algorithmically generated music or generative music is as old as Medieval times and is a well established art form, with Steve Reich and Brian Eno as well-known artists. A very nice introduction to generative music can be found here.
In my personal interpretation, generative music creates sounds that are perceptionally more complex than the seemingly simple rules that generate them.
Still thinking with my lazy cap on, which rules are the simplest yet create an abundance of complexity?
Wolfram and Cellular Automata
The graphics you have seen so far on this page have an interesting trait: the patterns seem to be repetitive yet with a degree of unpredictableness in it. They are technically not random - the images are generated using deterministic rules - but there is no simple explanation for this emergent behavior.
The rules used are elementary cellular automata and were popularized by Stephen Wolfram in his seminal book A New Kind of Science. What they do is the following:
- start with a row of 0s and 1s. These can be chosen arbitrarily;
- apply one of 256 elementary rules to this row;
- you obtain a new row with different 0s and 1s.
Here’s an example of how Rule 30 is applied. In our case we start with a row containing only zeros, except for the middle element:
Initial row: 0, 0, 0, 0, 1, 0, 0, 0, 0
Iteration 1: 0, 0, 0, 1, 1, 1, 0, 0, 0
Iteration 2: 0, 0, 1, 1, 0, 0, 1, 0, 0
Iteration 3: 0, 1, 1, 0, 1, 1, 1, 1, 0
As you see, we get a sequence of rows that are not quite repetitive yet also not entirely random. You could say that’s something we want out of music - a limited sequence of sounds that are somewhat repetitive yet not boring.
Music generated by cellular automata is already a thing: on Wolfram’s website there’s this incredible generator that I encourage you to play with.
Now, with me being stubborn and wanting to do things my own way, I decided to create a program from scratch that does roughly the same thing. For lack of imagination I decided to call it: Automatone.
Automatones

So, what is an Automatone? It is a matrix of zeros and ones, generated by cellular automata, where a one triggers a sound and a zero does nothing. For example, in the following matrix, three different sounds are triggered at different time intervals:
0, 0, 0, 0, 1, 0
0, 1, 0, 0, 0, 0
0, 0, 0, 1, 0, 0
If you imagine time going from left to right, and each row representing a different note or instrument, you can kind of imagine what it would sound like. In essence this is just another form of sheet music.
For the time being, I’m using a simple sine oscillator as an instrument, and let each row represent a different frequency of that instrument. To recap: each “one” in the matrix triggers a short sine tone with a specific frequency.
So what does this actually sound like?
Experiments
Going back a bit, I said I wanted to magically create music at the press of a button. The software I wrote can do that - follow the instructions on the main page if you want to experiment yourself!
Here’s a graph of a simple Automatone that applies Rule 30 to a range of 257 frequencies (vertical axis) for 256 time steps (horizontal axis):
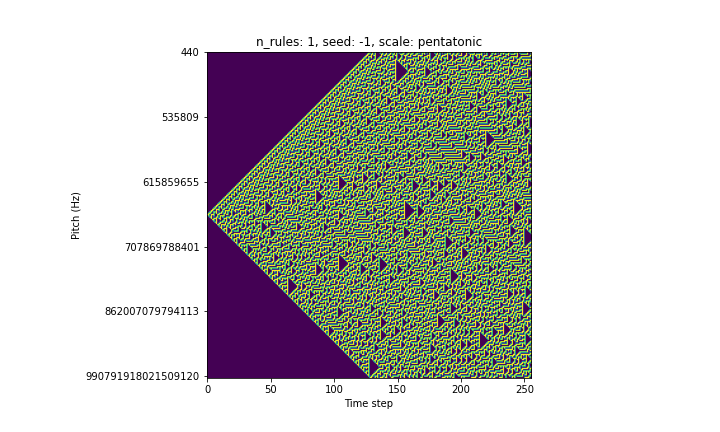
You can see that the frequency range is quite large - so large even that apart from the top 30 or so frequencies, the resulting output would be inaudible. Moreover, because I’ve set the rendering sample rate to 96kHz, there are a lot of artifacts. In other words, most inaudible frequencies are going to be rendered at a completely different (audible) frequency.
Not to worry though, because it sounds kinda cool - and to be honest, creepy!
Because there are a lot of tones being triggered together, it still sounds very random and unstructured. So, I included a parameter n_rules. This value indicates how many rules we are applying - if it is 2, then we take two cellular automaton rules and elementwise multiply the results with each other.
Here is another experiment where 5 rules are applied instead of one (we unfortunately don’t get to choose which rules, it’s something I still need to fix). I also limited the tone range to 24. You can see the trigger density is much lower:
And here, some more experiments. You can find the configuration parameters in the description of each link. What struck me is that there is still quite some repetition going on, possibly because of a bad implementation of the cellular automata:
Future work

I have many more ideas on how to proceed. The first is to use different combinations of rules for the left and right stereo tracks. The second is to combine all rules found in the left and right track to create a center track, which will - by definition - contain less triggers. In the next blog post I will try to elaborate on this. Thirdly, instead of multiplying each rule matrix I could also add them up and use the resulting value as a volume indicator.
Next I want to go deeper and use automata to create a change in the frequency spectrum rather than define it.
Ultimately, automata can be applied to any arbitrary instrument or effect setting: tweaking reverbs, phasers, delays, you name it. Even visuals can be manipulated like this.
Looking back, I made a thing that can automatically create “music” - however the sweat is now in creating the software rather than the music itself…
Thank you for your attention,
keepitwiel